
در چشمانداز پویای سال ۲۰۲۶، دستیارهای کدنویسی مبتنی بر هوش مصنوعی مولد به ابزاری جداییناپذیر برای توسعهدهندگان نرمافزار، مهندسان داده و متخصصان تحلیل داده تبدیل شدهاند. با معرفی پیاپی مدلهای متنباز و ابزارهای تجاری ابری، دسترسی به هوش مصنوعی دیگر یک چالش نیست؛ بلکه چالش اصلی، مدیریت بهینه منابع مالی و زمانی در هنگام استفاده از این فناوریهاست. بسیاری از توسعهدهندگان به طور پیشفرض برای تمام مراحل پروژه خود به سراغ اشتراکهای پولی مانند Claude Pro یا ChatGPT Plus میروند، اما تحلیلهای جدید و تجربیات عملی نشان میدهند که این رویکرد تکمدلی نه تنها از نظر اقتصادی پایدار نیست، بلکه جریان کار (Workflow) را با محدودیتهای شدیدی مواجه میکند.
در این مقاله تخصصی، استراتژی پیشرفته «برنامه نویسی ترکیبی یا هیبریدی» را کالبدشکافی میکنیم. این استراتژی که بر پایه تلفیق هوشمندانه مدلهای محلی (Local) و مدلهای قدرتمند ابری (Cloud) استوار است، به شما اجازه میدهد تا بدون افت کیفیت خروجی، هزینههای پردازش خود را به حداقل برسانید و محدودیتهای آزاردهنده مصرف ساعتی را به طور کامل دور بزنید.
چرا اتکای کامل به مدلهای ابری (Cloud LLMs) یک اشتباه استراتژیک و پرهزینه است؟
پرداخت هزینه ثابت ماهیانه (مانند ۲۰ دلار برای کلود پرو) در نگاه اول بسیار بهصرفه به نظر میرسد. شما تصور میکنید با این مبلغ به یک دستیار همهفنحریف دسترسی نامحدود دارید. اما واقعیتِ فرآیند برنامهنویسی کاملاً متفاوت است. توسعه نرمافزار فرآیندی کاملاً تکرارپذیر (Iterative)، مبتنی بر آزمون و خطا و نیازمند بازنویسیهای مداوم است.
بررسی دقیق الگوهای مصرف نشان میدهد که حتی با داشتن اشتراک پولی، توسعهدهندگان حرفهای در طول یک پروژه میانمدت ناچار میشوند مبالغ سنگینی (گاهی بیش از ۳۰۰ دلار در چند ماه) را صرف شارژ مجدد اعتبارات مصرفی (Top-up) کنند. دلیل این افزایش ناگهانی و پنهان هزینهها در مدلهای ابری به سه فاکتور کلیدی بازمیگردد:
- سربار عظیم کانتکست (Context Overhead): در پروژههای کدنویسی، شما معمولاً کل ساختار فایلها و کدهای قبلی را به هوش مصنوعی واگذار میکنید. با هر پرامپت جدید برای اصلاح یک خط کد، تمام این کانتکست حجیم مجدداً پردازش میشود و در هر ثانیه هزاران توکن مصرف میگردد.
- توکنهای تفکر و استدلال (Reasoning Tokens): مدلهای پیشرفته نسل جدید قبل از تولید پاسخ نهایی، زمان زیادی را صرف تفکر زنجیرهای داخلی میکنند. این فرآیند استدلال عمیق، تعداد توکنهای مصرفی را به شدت افزایش میدهد، پیش از آنکه حتی یک خط کد روی نمایشگر شما ظاهر شود.
- چرخههای طولانی آزمون و خطا: فرآیند رفع باگ شامل پیامهای متوالی نظیر «این کد کار نکرد»، «خطای جدیدی دریافت کردم» و «روش دیگری را امتحان کن» است. هر یک از این پیامها یک چرخه کامل مصرف توکن ابری را فعال میکند و در عرض چند ساعت، سقف استفاده ۵ ساعته یا روزانه شما را به طور کامل مسدود میسازد. در این حالت، جریان کار شما تا زمان ریست شدن محدودیتها کاملاً متوقف میشود.
فرمول جادویی: اجازه دهید سختافزار شما هزینه نرمافزار را جبران کند
پادزهر اصلی این چالش، بهرهگیری از مدلهای متنباز و قدرتمند محلی از طریق پلتفرمهایی مانند Ollama است. اگر روی سیستم خود از سختافزارهای مدرن (مانند کارتهای گرافیک سری RTX) استفاده میکنید، این قطعات میتوانند به عنوان یک نیروگاه پردازش هوش مصنوعی رایگان عمل کنند. با اجرای مدلهای لوکال، هزینه نهایی هر کوئری و فرآیند آزمون و خطا برای شما دقیقاً صفر خواهد بود.
اما از آنجایی که مدلهای محلی همچنان در زمینه استدلالهای بسیار پیچیده ساختاری و معماری کلان، کمی ضعیفتر از پرچمداران ابری مثل نسخه جدید Claude عمل میکنند، بهترین راهکار، پیادهسازی یک جریان کار سهمرحلهای و زنجیرهای است.
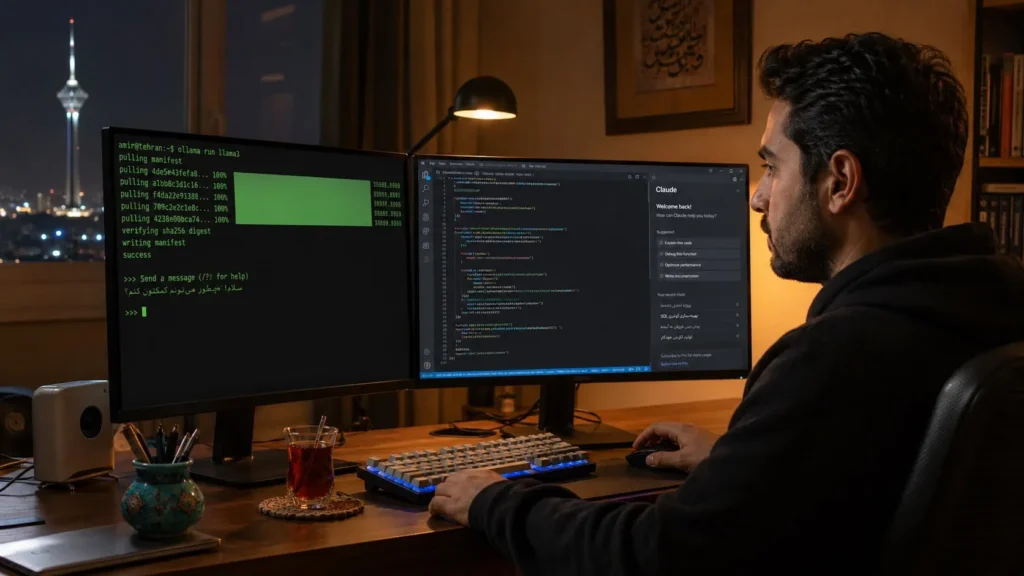
معماری سهمرحلهای کدنویسی ترکیبی (The 3-Step Hybrid Workflow)
برای پیادهسازی این استراتژی، پروژههای خود را به سه فاز مجزا تقسیم کنید و هر فاز را به مدلی بسپارید که بهترین بازدهی اقتصادی و فنی را دارد. به عنوان یک نمونه واقعی، فرآیند ساخت یک اپلیکیشن پایتون با کتابخانه PyGame را بررسی میکنیم:
گام اول: ایدهپردازی، طوفان فکری و ساختارشکنی با Gemma 4
در مراحل اولیه پروژه، شما نیازی به تولید کد ندارید، بلکه باید معماری و ابزارهای مناسب را انتخاب کنید. مدل متنباز گوگل، یعنی Gemma 4، ابزاری فوقالعاده برای طوفان فکری و بحثهای ساختاری است. در سناریوی ساخت اپلیکیشن، شما میتوانید مزایا و معایب استفاده از PyGame را در برابر Tkinter با این مدل به بحث بگذارید و ساختار کلی فایلها را مشخص کنید. این فاز به دلیل ماهیت مکالمهای، توکنهای زیادی مصرف میکند که اجرای آن روی مدل محلی Gemma 4 کاملاً رایگان تمام میشود.
گام دوم: نگارش کدهای پایه و اسکلتبندی با Qwen3-Coder
پس از تایید نقشه راه، نوبت به نوشتن توابع پایه، راهاندازی کلاسها و کدهای تکراری (Boilerplate) میرسد. مدل Qwen3-Coder پادشاه بیرقیب مدلهای محلی در حوزه برنامهنویسی است. این مدل متنباز کدهای پایه و توابع اولیه اپلیکیشن شما را با دقت و سرعت بالا تولید میکند. از آنجایی که فاز نگارش اسکلت اولیه کد بیشترین حجم توکن ورودی و خروجی را دارد، سپردن آن به Qwen3-Coder باعث میشود حدود دوسوم (۶۶٪) از کل کار توسعه بدون پرداخت حتی یک سنت انجام شود.
گام سوم: بهینهسازی، دیباگ عمیق و معماری نهایی با Claude
زمانی که کدهای پایه آماده شدند و پروژه شکل گرفت، نوبت به اعمال ظرافتهای فنی و حل باگهای پیچیده میرسد. در این مرحله، اسکریپت تولیدشده را به پلتفرم ابری Claude منتقل کنید. کلود با قدرت استدلال بینظیر خود، کدهای نوشتهشده توسط مدلهای لوکال را بازبینی (Refactor) کرده، خطاهای منطقی را برطرف میسازد و پایداری سیستم را تضمین میکند. در این حالت، شما از اعتبار پولی و ارزشمند ابری خود، صرفاً برای حیاتیترین و پیچیدهترین بخش پروژه استفاده کردهاید.
جدول مقایسه فنی و اقتصادی مدلها در جریان کار ترکیبی
در جدول زیر، نقش، بستر و مزیت اقتصادی هر یک از این سه ضلع مثلث کدنویسی ترکیبی را مشاهده میکنید:
| نام مدل هوش مصنوعی | بستر اجرای اصلی | هزینه پردازش و توکن | نقش کلیدی در جریان توسعه نرمافزار |
| Gemma 4 | محلی (Ollama / Local NPU) | کاملاً رایگان (صفر) | طوفان فکری، مقایسه فریمورکها و طراحی اولیه ساختار پروژه |
| Qwen3-Coder | محلی (Ollama / Local GPU) | کاملاً رایگان (صفر) | تولید کدهای پایه، نگارش اسکلت اصلی برنامه و توابع روتین |
| Claude (Sonnet/Opus) | سرورهای ابری (Cloud API) | مصرف اعتبارات پولی اشتراک | حل باگهای ساختاری عمیق، ریفکتور پیشرفته و تضمین امنیت کد |
نتیجهگیری نهایی: مدیریت هوشمندانه توکنها
موفقیت در عصر هوش مصنوعی، صرفاً به معنای استفاده از قویترین مدل نیست، بلکه به معنای استفاده هوشمندانه و بهصرفه از ابزارهاست. با زنجیر کردن مدلهای محلی مانند Qwen3-Coder و Gemma 4 به مدلهای ابری مثل Claude، شما یک سیستم پایدار، همیشه در دسترس و به شدت اقتصادی خلق میکنید. این روش نه تنها به سختافزار پردازشی شما هویت و کاربرد جدیدی میبخشد، بلکه مانع از هدررفت بودجه شما در چرخههای بیپایان آزمون و خطا میشود. هوشمندانه برنامهنویسی کنید تا تکرار و خطا، هزینه پردازش شما را سنگین نکند.



